Blog
FMAP v2: comparing a SciBERT classifier against the v1 TF-IDF baseline on astro-ph arXiv data
FMAP started with a deliberately simple classifier: TF-IDF features over paper titles and abstracts, followed by a LinearSVC. That was a sensible baseline. But once the project grew into real astro-ph ingestion, semantic retrieval, and an interactive paper atlas, it made sense to test a more expressive classifier too. This post compares the original v1 baseline against the new v2 SciBERT fine-tuning path on the same astro-ph arXiv dataset.
Dataset and setup
This comparison uses the retained astro-ph arXiv CSV produced by the FMAP ingestion pipeline. The current dataset contains 5,000 papers
across six astro-ph categories, with the usual FMAP 75/25 stratified train/test split and the same input text for both models:
title + abstract.
Class counts
- astro-ph.GA: 1268
- astro-ph.HE: 1059
- astro-ph.SR: 809
- astro-ph.CO: 740
- astro-ph.EP: 626
- astro-ph.IM: 498
Current corpus snapshot
- Source: arXiv export API via FMAP ingestion
- Scope: astro-ph only
- Rows retained: 5,000
- Train/test split: 75% / 25%
- Recent-tail heavy: 2025–2026 dominated
What changed from v1 to v2?
v1
The original classifier uses TF-IDF with unigram and bigram features, then a LinearSVC. It is fast, simple, interpretable, and still a very good baseline for scientific text classification.
v2
The new classifier fine-tunes allenai/scibert_scivocab_uncased for six-way astro-ph classification using PyTorch and Hugging Face. It is heavier and slower, but it can model context and scientific phrasing much more naturally than sparse TF-IDF features.
The important point is that FMAP now has a proper modelling ladder: a lightweight classical baseline and a more serious transformer path, both sitting on top of the same real arXiv ingestion pipeline.
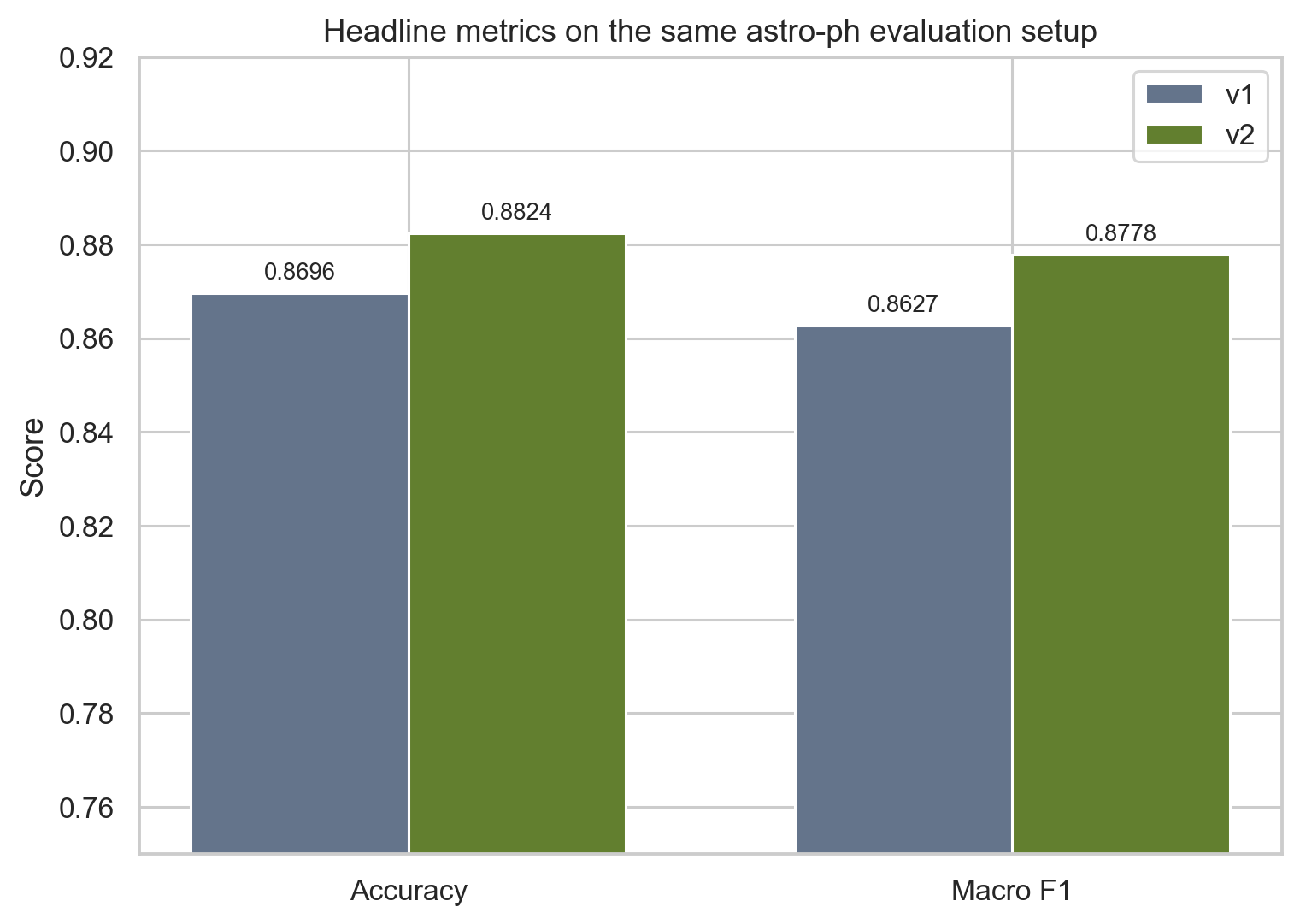
Headline results
The cleanest summary is simple: the transformer wins, but not by some silly margin. That is actually what makes the result believable. The baseline was already doing real work, and v2 improves on it rather than replacing a toy.
| Model | Text representation | Classifier | Accuracy | Macro F1 | Notes |
|---|---|---|---|---|---|
| v1 | TF-IDF (unigrams + bigrams) | LinearSVC | 0.8696 | 0.8627 | Fast baseline, light to train, still strong |
| v2 | SciBERT fine-tuning | Transformer classifier | 0.8824 | 0.8778 | Better contextual modelling on scientific text |
Overall delta
- Accuracy: +0.0128
- Macro F1: +0.0151
- Best gain: astro-ph.IM (+0.0420 F1)
- Other strong gains: astro-ph.CO, astro-ph.GA
Read it plainly
v2 is not an absurd leap over the baseline, which is actually a good sign. The v1 model was already decent. But the transformer does improve the aggregate metrics, and it helps most on the more awkward or overlapping parts of the label space.
Per-class changes
Looking only at the headline metrics hides the more interesting story. The useful question is where the transformer helps, and where the classical baseline remains competitive.
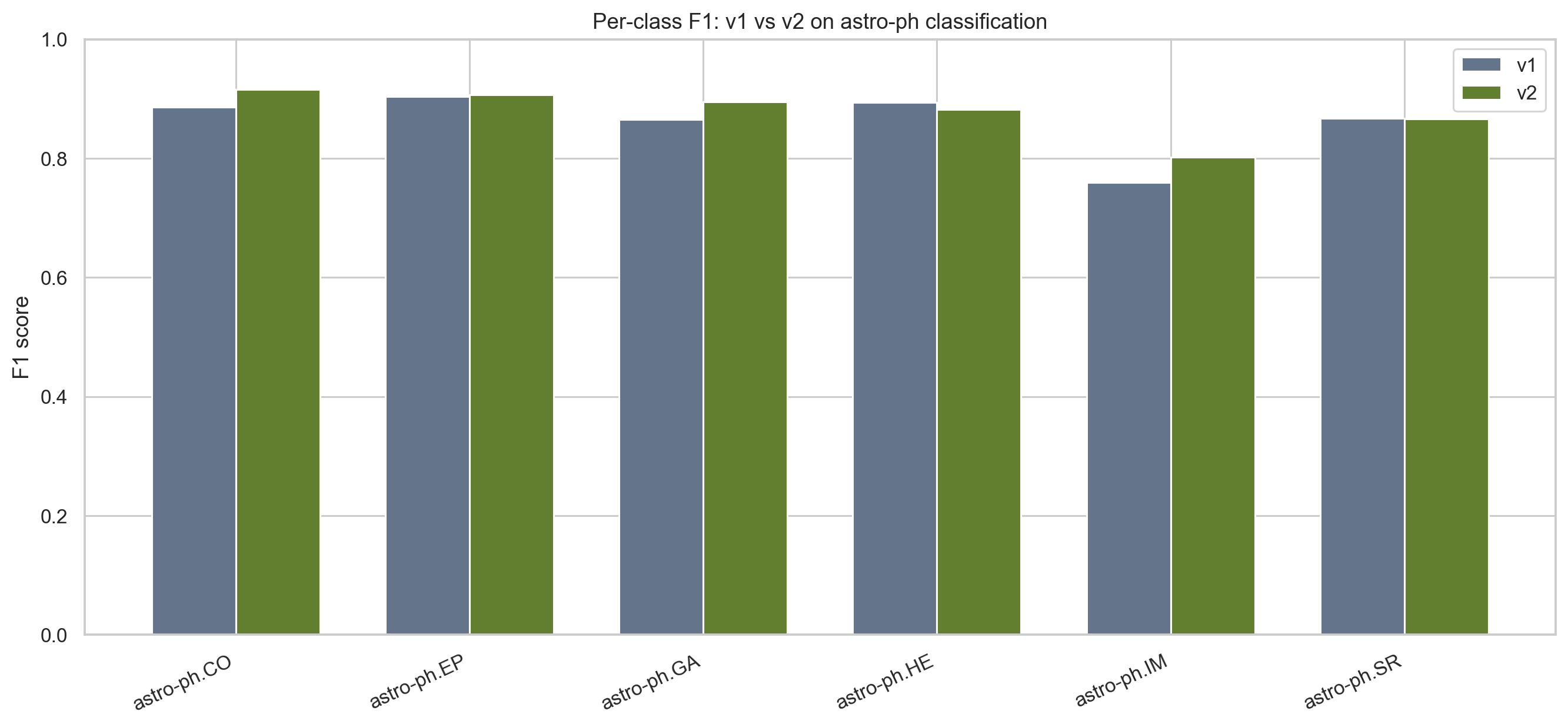
| Class | v1 F1 | v2 F1 | Delta |
|---|---|---|---|
| astro-ph.CO | 0.8864 | 0.9160 | +0.0296 |
| astro-ph.EP | 0.9038 | 0.9068 | +0.0030 |
| astro-ph.GA | 0.8654 | 0.8946 | +0.0291 |
| astro-ph.HE | 0.8939 | 0.8818 | -0.0121 |
| astro-ph.IM | 0.7595 | 0.8015 | +0.0420 |
| astro-ph.SR | 0.8672 | 0.8660 | -0.0012 |
The biggest improvement is in astro-ph.IM, which is exactly the kind of class where I would hope a contextual model helps. Instrumentation language often bleeds into observational and analysis-heavy work, so sparse term counting can struggle.
astro-ph.CO and astro-ph.GA also improve noticeably, suggesting that the transformer is picking up useful phrase-level structure rather than just keyword frequency.
The two classes that do not improve here are astro-ph.HE and astro-ph.SR, though SR is basically flat. That is a useful reminder that a bigger model does not magically dominate every label.
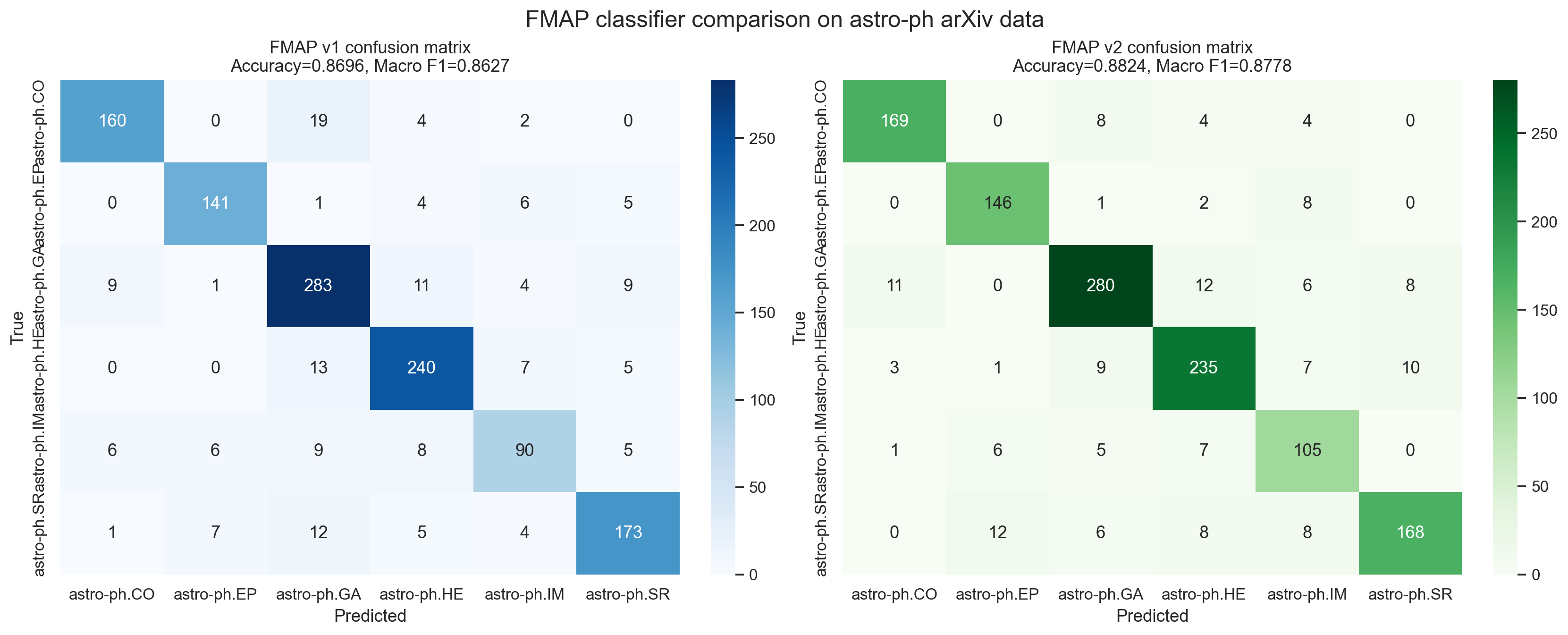
Confusion matrices, side by side
The most intuitive visual comparison is the confusion matrix. You can see the same test set through two different classifiers and ask whether the errors become cleaner, more concentrated, and more astrophysically sensible.
Method, a bit more formally
There are really two mathematical stories in FMAP. The first is the supervised classifier, where the goal is to assign each paper to one astro-ph label. The second is the embedding-and-map pipeline, where the goal is to preserve semantic neighborhoods well enough for search and visualization.
v1: linear classification in sparse feature space
In the baseline model, each paper is represented by a TF-IDF vector x_d in R^V, where V is the vocabulary size after feature selection.
The classifier then learns a linear score for each class:
and predicts
This is a good fit when categories are associated with stable terminology, characteristic phrases, and fairly separable sparse statistics.
v2: contextual representation + classification head
In v2, the title and abstract are tokenized and passed through SciBERT, producing a contextual representation h_d for the document.
The classification head then produces logits
and the class probabilities are given by softmax:
Training minimizes cross-entropy over the labelled astro-ph categories. The key difference from v1 is that h_d depends on context, not just counts.
Embedding similarity
For retrieval and mapping, FMAP uses dense sentence embeddings e_d. Similarity is computed with cosine similarity,
which reduces to a dot product when the embeddings are normalized:
Why macro F1 matters
Because the six classes are not perfectly balanced, macro F1 is a better summary than raw accuracy alone. For each class,
and the reported macro F1 is the unweighted mean over classes:
UMAP then takes the dense embedding geometry and produces a two-dimensional representation that tries to preserve local neighborhood structure. That is why it is useful for the atlas: the objective is not just a pretty scatter plot, but a map where nearby papers tend to be semantically related.
Why v2 helps
Scientific abstracts are not just bags of words. A lot of the distinction between neighboring astro-ph categories lives in how ideas are phrased together: measurement language, observational context, inference framing, and domain-specific combinations of terms. SciBERT is a better match for that kind of text than TF-IDF.
Even when the raw metric gain is modest, v2 also matters because it opens a better research path: different backbones, class weighting, better calibration, and potential links between classification and retrieval objectives later on.
The real takeaway
The best part of this comparison is not just that v2 wins. It is that FMAP now has a more honest and useful project structure. There is a baseline that is cheap, explainable, and worth keeping. And there is a stronger contextual model that performs better on the same real astro-ph pipeline.
That is the kind of progression I like in portfolio work: start with the simple method that earns its place, then add complexity only when it buys something real. In this case, it does.
References and useful papers
If I were extending this project further, these are the papers I would keep closest to hand. They are the most relevant references for the transformer classifier, the embedding setup, the baseline model choice, and the geometry of the atlas itself.
Vaswani et al. (2017). Attention Is All You Need.
https://arxiv.org/abs/1706.03762
Devlin et al. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
https://arxiv.org/abs/1810.04805
Beltagy, Lo, and Cohan (2019). SciBERT: A Pretrained Language Model for Scientific Text.
https://arxiv.org/abs/1903.10676
ACL version: https://aclanthology.org/D19-1371/
Reimers and Gurevych (2019). Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks.
https://arxiv.org/abs/1908.10084
McInnes, Healy, and Melville (2018). UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction.
https://arxiv.org/abs/1802.03426
Joachims (1998). Text Categorization with Support Vector Machines: Learning with Many Relevant Features.
https://www.cs.cornell.edu/people/tj/publications/joachims_98a.pdf